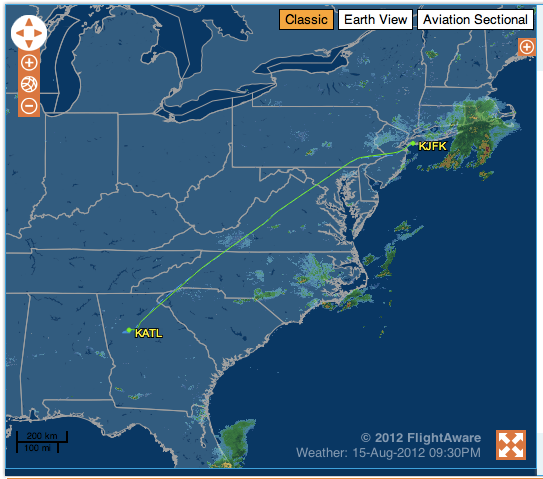
Delta Air Lines tells me it will take two hours and twenty-five minutes to fly from New York City to Atlanta, GA. American says two thirty. United? Two thirty-four. Yet, the captain just told me it was “one-hour forty-five” minutes “wheels-up to wheels-down”. What gives?
It turns out that the US Department of Transportation (US DOT) rates the airlines by “on-time performance”: whether or not the aircraft reaches the gate by the quoted time. So, like any rational actors, the airlines pad the flight time to account for ground delays (waiting by the gate for the tug driver to appear), re-routes due to bad weather, etc. – but also to goose the ratings.
They could massively pad and say the flight takes three hours, but that impacts the ability for folks to connect to other flights. Airlines constantly tweak the advertised flight time: too much padding and the wasted time on the ground costs dearly; too little and the DOT will come after you.
Software
Software developers are often called upon to estimate various tasks, features, or bugs. Oftentimes this is measured in hours, but for larger stories it could be days or weeks (month-long estimates don’t seem to be as common).
These estimates are used to estimate the effort for a given task and, in the hands of a business user/project manager, added up to get the completion date for the project as a whole (e.g. feature X takes 2 weeks, feature Y takes 3, X + Y = 5 weeks to launch). This completion date is then used in a formula to calculate total project cost (salary per day * days, or equivalent).
In really terrible places to work, someone other than the developer will actually do the estimating. This estimate will then be given to the developer as an implicit (or at especially evil places, explicit) time not to exceed. This is such a depressing situation I cannot dare think of it further.

Estimation Process
The estimation process itself is not very well defined at many software companies. Often the developer will try and compare feature X to a known feature they have completed in the past. For example, “Create login form” may have taken them four hours on a previous project, so they can reasonably estimate likewise for a login form on a new project. Or, “Add a customer” seems a little bit harder than a login form, so multiply the login form estimate by 1.5x to get 6 hours.
It gets a lot trickier for larger features, like “Customer Analytics”. What does “Customer Analytics” mean? Hopefully the developer has been given a specifications document from a business analyst (or equivalent) that spells out all of the requirements:
- Bar chart of Customers over time (group by signup date)
- Ability to change scale (view week, month, year)
- Exclude inactive Customers
- etc.
In this case, the smart developer would decompose the feature into smaller features that can be compared to past experiences. The dumb developer would try and estimate the feature as a whole. Bad, naughty developer!
Missing Data
Most estimation is drawn from past experience. What if the developer doesn’t have this experience? How can they estimate? This is where things get tricky. And by tricky, I mean “completely made up.” Sure, for things that have been done before by someone the developer can draw some parallels and make a guesstimate. But what about the stuff that has never been done before (presumably, the secret-sauce that makes you money)? Usually you just take a Wild-Ass Guess (WAG-estimation) and hope you’re not wrong. Given the rarity of being punished for under-promising and over-delivering this WAG tends to be a massive over-estimation.
Effort vs. Accuracy
It seems obvious that the more time you spend on your estimates, the more likely you are to “get it right.” Right? This thesis is basically the entire justification for the Waterfall model of software development.
Completely spec out the entire system ahead of time, spend a lot of time researching and estimating the problem, determine project dependencies, and you can determine the “finish date” before writing a line of code! It’s seductive and taps into the part of our brain that craves order and dependability.

It turns out that effort spent estimating only provides marginal returns and, eventually, becomes negative. Why? Because of overfitting.
In machine learning, overfitting generally results from having too little training data (edited: incorrect usage of test data) or focusing on irrelevant metrics. The costing algorithm you evolve into can only accurately predict your training data. When fed a new problem the algorithm provides widely variable or incorrect information.
Human estimation algorithms fall into the same trap – the more you try and dig into a problem, the more you see parallels that don’t exist and the less you account for randomness (or “unknown unknowns”). You end up being very confident in your estimation but ultimately are wildly wrong.

Why Estimate?
Let’s back up a bit. Earlier I wrote that folks estimate in order to determine the completion date for the project as a whole.
And? What’s the point of knowing when the entire project will be complete? Who cares? Typical answers are:

- So we know whether or not to undertake the task
- So we know how many developers to put on the problem
- So we don’t overspend
- So they can generate a ship date for marketing/PR reasons
But I think the deeper, much-less admitted reason is that managers and other “business people” don’t do a particularly good job of calculating business value, motivating, and managing software people and projects. They wield the estimate as a cudgel: perform X by Y date or else.
Business Value Knife Fight
In his 1986 book, “Controlling Software Projects: Management, Measurement, and Estimation” Tom DeMarco (yes, of Peopleware fame) wrote “You can’t control what you can’t measure.” This is true, but is it important in software projects? Some 23 years later Tom doesn’t think so.
“You can’t control what you can’t measure.” This line contains a real truth,
but I’ve become increasingly uncomfortable with my use of it. Implicit in
the quote (and indeed in the book’s title) is that control is an important
aspect, maybe the most important, of any software project. But it isn’t.
The full article text is here.
Tom goes further to state:
My early metrics book […] played a role in the way many budding software
engineers quantified work and planned their projects. In my reflective mood,
I’m wondering, was its advice correct at the time, is it still relevant, and do
I still believe that metrics are a must for any successful software development
effort? My answers are no, no, and no.
The tl;dr of his article is that the software projects that require tight cost control are the ones delivering little or no marginal value. That is,
To understand control’s real role, you need to distinguish between two drastically
different kinds of projects:* Project A will eventually cost about a million dollars and produce value of around $1.1 million.
* Project B will eventually cost about a million dollars and produce value of more than $50 million.What’s immediately apparent is that control is really important for Project A but
almost not at all important for Project B. This leads us to the odd conclusion
that strict control is something that matters a lot on relatively useless projects
and much less on useful projects. It suggests that the more you focus on control,
the more likely you’re working on a project that’s striving to deliver something
of relatively minor value.To my mind, the question that’s much more important than how to control a software project is, why on earth are we doing so many projects that deliver such marginal value?
If the value of software we’re writing is so low, is it worth being written? If the project has such tight time constraints that a schedule slip will doom the project then you’re in a world of hurt. (The solution is agile: work on the most important things first, have an always-working project, and cut scope to hit a date.)
This exposes a major weakness in most software companies: the inability to determine project value. Given a project of unknown value, the conservative business will then attempt to minimize cost. Unfortunately as we’ll see, cost minimization ends up becoming very expensive in the long run.
Hierarchy as a Service
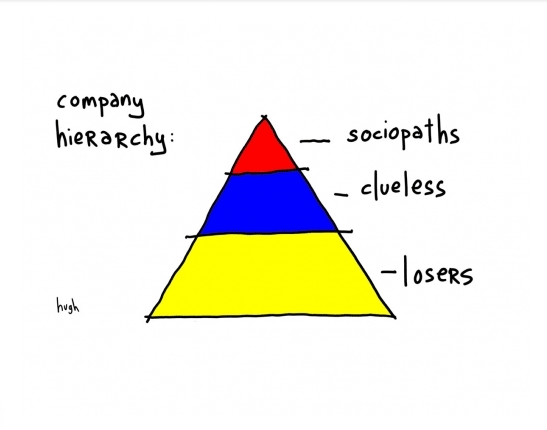
Most companies are incredibly hierarchical – programmers report to a tech lead who reports (tangentially, to a project manager) to a mid-manager who has one or two layers in-between them and the CIO/CTO/CEO. The further up the stack the greater the nosebleed: the lack of visibility of the day-to-day machinations of the software organization and the less concrete decision making (aka vision over strategy/tactics).
This results in senior/mid tier managers that don’t know much about how software actually gets written. Given the perverse cost-minimization (because they didn’t do their job) organizations go to great lengths (of both time and money) to keep projects under tight control:
- They require big up front design before any code is worked on
- They require sign-offs and constant oversight
- Anything that isn’t directly driving completion of a task is forbidden (or at least, implicitly disincentivized)
What does this do? It encourages waste via Parkinson’s Law. It discourages refactoring when software entropy becomes unmanageable. Ultimately, estimation ensures software projects underachieve. By strictly managing cost, an organization guarantees the value is strictly limited.
(I’m not entirely sure what this means, but I’ve never seen the folks who are writting the specs, requirements, etc. ever being asked to estimate how long each spec will take to write. Or have the CEO give a date when the company will hit some arbitrary metric, although see the perversity in public company earnings estimates and reporting.)
Trust me, I’m Lying

Ultimately companies require estimation because they don’t trust anyone. They don’t trust developers to deliver results. They don’t trust mid-management to motivate their reports. The underlying reality is that the folks “in charge” are worried that everyone is going to rip off the company and only by holding people to arbitrary deadlines are they assured stuff will get done.
Committing to a date allows them to sleep better at night and shifts the blame from them to the folks on the front lines. And this is wrong, both morally and from a pure technical perspective. (See: Results Only Work Environment for how to manage based on results.)
Estimation considered harmful
Estimation is ultimately a futile effort. Software, more or less, is like writing poetry. Or solving mathematical proofs. It takes as long as it takes, and it’s done when it’s done. Perfect, or imperfect, estimation won’t change how long it takes to complete the work. If that sounds horrible to you, then go do something else.
Even if we could completely accurately estimate all of the pieces, software of any complexity has interdependencies and “unknown unknowns” that tend to not surface until implementation time. You can’t know the end date a priori by simply adding up all the components.
Estimation actually slows down development because estimation isn’t free. The developer is incentivised to take as long as possible estimating in an effort to not get beaten when they miss the estimate. Why waste that time when the metric the developer is attempting to hit ultimately generates negative value?
(In Peopleware they discovered that projects where no estimation was done had the highest average productivity; any estimation lowered productivity no matter who performed the estimation.)

Software is not like bricklaying – you can’t speed it up without major consequences. The Mythical Man-Month teaches us that adding developers to a late project will only make it later due to exponential communication and ramp-up (coined “Brook’s Law”).
This results in folks that think adding more developers to a project at the beginning will allow them to hit an arbitrary date by spreading out the workload. Unfortunately new software doesn’t work this way, either, as the same exponential communication overhead occurs in the beginning, too. You merely end up with a giant mass of incoherent code. And you waste a lot of money employing people who don’t add much value, sitting on the bench waiting for their part of the project to begin.
The solution is “Don’t build big software”, which I’ll cover in a future post.
Two Points for Honesty
Estimation isn’t all bad, though. The act of estimating forces you to consider the problem domain in some detail. As Winston Churchill said, “Failure to plan is planning to fail.”
This is why I espouse the agile activity of relative points-based estimation. Regardless of which point system you use (linear, exponential, etc.) group-based estimation helps the entire team arrive at a shared understanding of what each feature/story/etc. is supposed to do. This is critical to keeping a high bus factor.
The key point is that these estimates are never, ever used to try and pinpoint a “ship date” (you should be using continuous deployment anyway) or used to punish a developer for “taking too long”.
The estimation process should take place relatively quickly. Break stories up into trivial tasks (which by definition don’t need estimating) and then roughly estimate the risk posed by other stories (external integrations, hard machine learning problems, etc.). In all, this process shouldn’t take very long.
This ensures minimal estimation waste, keeps developers happy, and velocity high.
(UPDATE) Evidence of What?
Some folks have asked: “What about evidence-based scheduling?”
That’s a very good question. I have a huge man-crush on Joel. Probably so much that if I saw him in person I’d babble like a child and be basically incoherent. He’s done more to advance the state of programmer work environments and software development than anyone I can think of in recent history.
Joel doesn’t strike me as the kind of guy who would use hourly estimates to punish developers. So, I think it comes from a good place, and not the deep-dark evil place that most estimation requirements come from. But, when it comes to EBS, I’m not sure it really provides that much value relative to the overhead vs. relative points-based.
It’s really close to what agile points give, namely a burndown chart, except you’ve got all the overhead of keeping track of exactly how long it takes to finish (I admit that I may be overestimating the time it takes to manage this reporting.)
Even if it’s easy to record the hours, I’m still skeptical that things like Parkinson’s Law might intrude or that the psychological effects of hours-based estimation may have unintended consequences. I’d rather stick to points.
Click here for the Hacker News discussion
Defensive Disclaimer
Building safety-critical software is necessarily out of scope, as that is a completely different animal. I’ve never built space shuttle software or something that could easily kill someone so the suitability of this technique is undefined.