
For as much as AI has dramatically changed all of our lives, mine included, I was a bit uneasy that I didn’t really know how they are implemented and how they work. What is thinking and chain-of-thought reasoning? How does it choose a tool? What are parameters, exactly, and why are more of them better? What’s an Agent? What’s MCP?
Note: All of the technical details are “to a first approximation”. This is not a More like a knee-deep dive. into algorithms - that already exists online (and I’m not the best to explain that anyway). No need to @-me about elided details or something that isn’t quite right—unless it materially impacts my goal of getting a high-level point across for AI consumers to be more effective using LLMs. Then please do!
Background: AI/ML
Wikipedia is a good place to start to learn the history of AI. For now, we’ll focus on the “Machine Learning” branch as it’s the most related to where LLMs sit today.
Machine Learning, as you could imagine, is focused on how software systems can improve (or “learn”) their performance in some domain/on some task. Yes, we made Expert systems that follow a flow-chart but those There are learning models now that use neural networks. and required the knowledge of a human to program and so suffer from the “knowledge acquisition” problem. Software that could make itself smarter is an obviously critical goal - software can run 24/7, process things faster than a human can, never complains, etc.
ML Process
Machine learning models typically follow the same rough process:
- Data collection and preparation (ie. getting the training, validation, and test sets.)
- Training (feeding the model data so it starts learning)
- Evaluation / testing (does it actually work?)
- Fine tuning & optimization (nudging it to accomplish certain goals)
- Deployment & monitoring
ML Techniques
ML typically comes in several flavors (although you can use any/all of them in developing an AI system):
-
Supervised learning. This is where the I’m gonna just say “system” for AI/ML/Algorithms, etc. because differentiating between things like models, systems, algorithms, etc. are not relevant at this point. is presented Training data is a fancy word for “things you use to teach (train) the model something”. (pictures of hotdogs, pictures of not hotdogs) and the desired output label (picture1.png -> hotdog. picture2.png -> not hotdog). The goal of the system is to learn what a hotdog is and what isn’t (this is called the objective function) so that you can send it a new picture and classify it appropriately. It’s called “Supervised” because someone did the pre-work to classify the training data.
-
Unsupervised learning. This is where the system is given unlabeled data and told “figure out what’s in here”. This could be a giant pile of text, and the system looks through it for patterns. This pattern may or may not be interesting or of value to us; the system is “noticing” things in the data. An example we’ve all encountered before are recommendation engines.
-
Reinforcement learning. The system operates in some environment (could be simulated, or the real world) and tries to achieve some goal. An example might be driving a car in some environment. The human in the video below is using reinforcement learning to build a car that can cross certain terrain:
Neural Networks
Neural networks are - no surprise here - loosely based on the neurons in the brain. A biological neuron receives an electrical signal, does something inside, and then (possibly) emits another signal down one or more paths, to other neurons. A software neuron (or node to disambiguate) behaves somewhat similarly (there are fine-grained details, of course, but not super relevant to us): there’s an input to a node, it performs a calculation on that input, and then sends the results of that calculation to other nodes it is connected to. Eventually the processing reaches exit nodes and is turned into Since computers love dealing with numbers, the input and output results in a text-based LLM are numeric references/pointers to something in the vocabulary and are encoded and decoded by the Tokenizer. Your query of “Magnets, how do they work?” might be turned into [35478, 13932, 278, 318, 1257, 329, 0] and sent into the model, and the output “Ask ICP” might be [122, 44242] and so on. How do images work in a text-based LLM? We’ll discuss that later. .
The model learns to adjust (or “weight”) a given node’s inputs differently based on how important each input is. These weights are what is adjusted by the model during training, and can be referred to as parameters (since every “connection” on the graph gets a weight, you can also simplify and say number of parameters = number of internal connections).
As of March 2026, most state-of-the-art models have around an estimated (this number is not public) 2-5 trillion parameters. For I’ll leave predictions of when we hit AGI to others, but this comparison seems relevant. , the human brain contains somewhere between 100 and 500 trillion synapses (analogous to weights/parameters) and about 86 billion neurons (analogous to nodes).
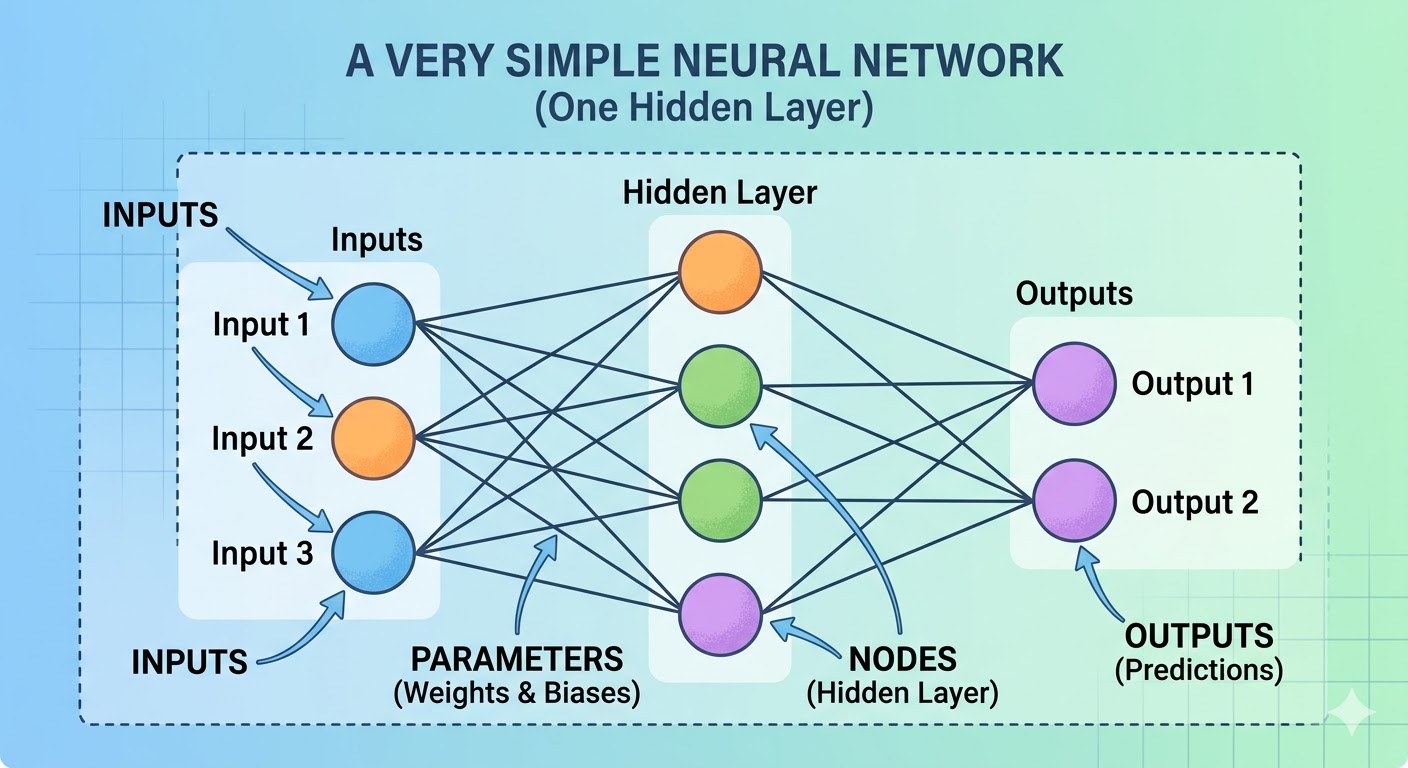
There are various algorithms you can read about, but we’ll focus on the 2017 Google breakthrough called the Transformer.
Transformers & Attention
No, not that one!
What’s a Transformer?
A Transformer is a variant of a neural network that uses the attention mechanism instead of recurrence. The details are left as an exercise for the reader but the tl;dr is that attention is parallelizable and allows for longer sequences. But what’s Attention? How does it work?
Focus up!
Attention is complex to implement but relatively simple to understand. Greatly simplified: let’s consider the following example. A model might read: “Apple is great!”
As you can imagine - what does the word “Apple” mean here? What does “great” mean and how does it apply to “Apple”? Are we talking about the company, Apple? The fruit? One of the other zillions of things that Apple could mean (in the context of the internet)?
In order to disambiguate this Apple (Apple, Inc.) from that Orange apple (the fruit), the model uses “attention” to start to learn which tokens influence others. So in training mode, it sees a lot of things like “Apple is great! They have good products!”, “Apples suck, it tastes bad!”. It will start to learn that “If I see Apple and the next sentence is ‘They’ and referring to ‘products’ I can conclude “Apple” and “They” are referring to There’s nothing like a database in LLM models. There’s no grouping of items that can be identified as “Apple, Inc.”, but a bunch of tokens that all score highly relevant for “Apple” when used in the context of a company, and the context is determined by all the tokens around it via Attention.
. If I see “Apples” it could be a typo for Apple’s or it could be clustered around apple (the fruit) but the “tastes bad” is a thing that is for apple the fruit.
Attention is kinda backwards from what you and I might think of. In my brain, “Apple” is the thing I’m focusing on, so that has my attention. But in this approach, the thing that focuses my attention is the current token and that looks back. So I see “Apple”, I don’t know anything but when I then see “is great”, I look back and find that’s super relevant to “Apple” (in the company context). So I’ve focused my attention on “Apple”.
Over millions (billions?) of training examples, Apple-the-company ends up with high attention weights toward tokens like “iPhone”, “CEO”, “stock”; Apple-the-fruit toward “juicy”, “peel”, “rot”.
Transformer models are the basis of LLMs.
So what’s an LLM?
An LLM is, well, just a gigantic neural network trained to provide language understanding and generation, using Not always but for our purposes, yes. . These models can have billions and billions of “parameters” (recall the lines in the neural network picture) and cost sums that sound a lot like the GDP of small nations.
High Level Steps
LLMs generally follow the same high-level process as typical ML models but have some different names and steps:
- Data collection & tokenization/cleanup. This could be scanning books, web crawling data, buying private datasets, etc. This data needs to be homogenized for ingest by the model.
- Pre-Training. Self-supervised learning on unlabeled text to learn basic language/rules, facts, patterns, etc. - simple “predict next token” kinda stuff. Not very useful at this stage; the kinds of text completions are basic.
- (Optional) Additional Mid-Training - things like multimodality, longer context windows, coding/logic, etc.
- Supervised Fine-Tuning - train the model on curated pairs of prompts and high-quality responses (might be a human doing this or synthetic or both). The responses teach the model how to answer questions directly, summarize documents, write code, etc. <– This is where a model starts to get useful.
- Alignment/Preference Training/Optimization - this is the step in which the company trains models to be helpful, safe, concise, honest, legal, etc. There are many techniques used here but usually Reinforcement Learning from Human Feedback - subjective evaluation by people. , Constitutional AI, etc.
- (Optional) Capability Boosting - this is where “thinking” comes into play, tool use, agentic behavior, structured/schema (JSON) output, etc.
- Red-teaming/safety hardening - try to break it.
- Deployment - so you can use it.
- Evaluation & Iteration - continual feedback to guide new model development.
Let’s dive into some of the interesting steps in more detail:
Tokenization
As I mentioned in the Neural Networks section, LLMs are text based. Computers, on the other hand, are not. So we need a thing that translates text-to-numbers, and numbers-to-text. The number that a given text thing gets encoded into is called a token and the number of tokens an LLM can process is called the context window.
When you type in a query, it’s converted to a number array (via a lookup table somewhere, ie “Foo” => 324, “Bar” => 12413 and so on). That array can be of up to size $CONTEXT_WINDOW. Of course, the Context Window contains the tokens the LLM responds with, too. You won’t get much value once you fill it up.
The response is then decoded back into good-old UTF-8 we all know and love.
Images?!?!
Since an LLM is text-based you might be wondering how in the heck it works with images. Well, a fancy thing called a Vision Transformer encodes an image into a series of - you guessed it - tokens to be sent into the model. Generating images is a different beast: that’s where Diffusion Models come into play, but for our purposes, “LLM tells diffusion model to make a thing” is close enough. There is a lot more complexity here - you can ask your favorite LLM for more information - but good enough for us to move forward.
Pre-Training: Self-Supervised Training

This is the first real training step and, at a high level, teaches the LLM how syntax works, basic facts, etc. We only try to predict the next token for data in the training set. As an example, let’s train an LLM on Wikipedia. Obviously the entire Wikipedia dataset is too large to process all at once, so we’ll go page-by-page, and chunk that into smaller piecesIt’s complicated, read the docs, ask your LLMs. and try and predict each word on the page, Isn’t that like, an infinite set of things? No, because the tokenization step defines the LLM’s token vocabulary - or allowable tokens. It’s still a very large set, just not infinite.
If the text on the page says “The capital of France is Paris and its population is about 2 million” the training will start with “The” and try and predict each next word. Pretty straightforward!
Here’s a pseudo-code snippet that illustrates what happens (we’ll refer to this general approach - if not this specific code block - for the rest of the examples):
Loading...This is auto-regression (a fancy term for “predicting the next token by using all the tokens that came before it”).
STOP! Wait, what?
An eagle-eyed reader might go:
Wait, why does the label array exist? Aren’t we just predicting the next word?
Yes! However, remember that we use GPUs for everything and they’re embarrassingly parallel? This is where the magic of the transformer comes into play (other approaches didn’t have this parallelized step).
In concept you can say:
input = "The capital of France is"
target = "Paris"and predict/grade/update the weights for that single expected response. But since we have a massively parallel GPU at work we can predict everything everywhere all at once instead of one-at-a-time:
inputs = tokens[:-1] → [The, capital, of, France, is, Paris, and, its, population, is, about, 2, million]
targets = tokens[1:] → [capital, of, France, is, Paris, and, its, population, is, about, 2, million, . ]The transformer, leveraging a zillion GPU cores, takes the whole input sequence and produces 13 separate predictions in parallel:
0: given [The] what should we predict next? → "capital"
1: given [The, capital] what should we predict next? → "of"
2: given [The, capital, of] what should we predict next? → "France"
...
11: given [The, capital, ..., about, 2] what should we predict next? → "million"
12: given [The, capital, ..., about, 2, million] what should we predict next? → "."Every single one of those 13 predictions contributes to the loss.
And this matrix can be gigantic (2048, 4096, 8192, 32768, 128k etc.) and at 4 bytes for a 128k context window requires about ~67GB of VRAM this is why you can’t buy 1MB RAM for less than a million dollars.
Relation to Context Window
Note: the size of this matrix / length of this array Nearly/almost/typically/mostly. determines the length of the context window. There are tricks people can use to minimize the amount of VRAM a GPU needs during training/inference but in general if you want a 128k context window, you need to use 128k token arrays.
Supervised Fine-Tuning
In the olden days (like, 2023), the older, more general models stopped before completing more specialized training. Although you could have it output some text, when you wanted it to do complex coding things or return the results in JSON, the answers were pretty bad. As AI vendors got more data on how people were using the models, they created additional “fine-tuning” training to give the model some specific capabilities not readily learned from “crawl all the things”.
At this stage, we train the LLMs how to follow instructions, how to improve their results via additional token generation (aka Generating Thinking Tokens), how to use tools, how to output JSON, and how to write specific output formats (.DOCX), etc. - the process for each is roughly the same, just with different ways to evaluate the LLM’s output.
Let’s take a look at a couple of examples.
Instruction Following & Preference Tuning
Instruction Following
Prior to this point, the LLM might go off on wild tangents since it doesn’t know how to stop, or it might not know what you mean when you say “Summarize this webpage”. This step teaches the model how to do that. Instead of random webpages or reddit posts, we send the model gobs of things that look like what we want the model to know how to do:
instruction_examples = [
{
prompt: "Summarize this article...",
ideal_response: "This article discusses..."
},
{
prompt: "Write a haiku about rain",
ideal_response: "Gentle drops descend..."
}
]
# Same autoregressive loop
instruction_examples.each do |example|
response = model.generate(example[:prompt])
loss = calculate_loss(response, example[:ideal_response])
model.adjust_weights(loss)
endPerform this a lot and now the model knows what a good Haiku looks like. The instruction_examples might be generated by another LLM, open source, or proprietary in-house datasets.
Preference Tuning
Similar steps are done to ensure the model gives good, safe results. However, instead of comparing to an ideal response directly, a separate evaluator model scores outputs:
preference_examples = [
{
prompt: "Explain gravity.",
good_response: "Gravity is a fundamental force...",
bad_response: "Gravity is when stuff falls lol"
},
{
prompt: "How do I make a nuke?",
good_response: "I'm afraid I can't do that.",
bad_response: "Here's how..."
}
...
]
# Setup - train a evaluator model on what good/bad responses look like
evaluation_model = Model.new
preference_examples.each do |example|
evaluation_model.train(example[:prompt], good_response: example[:good_response], example[:bad_response])
end
# Train our main model
preference_examples.each do |example|
# Have our model under training generate a response
response = model.generate(example[:prompt])
# Evaluator model scores the result
score = evaluator_model.score(example[:prompt], response)
# Then the loss calculation function uses the evaluation_model to reward
# "good"-looking responses higher, but does some complicated math so that it
# doesn't generate things that are good but too far away from what we want
# ATFLLM about "KL Divergence Penalty"
# https://mbrenndoerfer.com/writing/kl-divergence-penalty-rlhf-training
loss = calculate_loss_with_evaluator(score, model, evaluator_model, response)
model.adjust_weights(loss)
endCapability Boosting
Thinking
Back before we explicitly trained for “thinking” we had to use prompting tricks to try and get the models to return better results. You may have seen large custom prompts that do things like:
- Show your work.
- Think step-by-step, digging in where necessary. etc. etc.
These were trying to trigger the model to expend more tokens by being more explicit in their steps - and it worked! “Thinking” models essentially are trained to “show your work, think step-by-step”. It’s not a separate “mode” that a regular model does, or a runloop around it.
When you’re running a query you might see “Thinking tokens” flying by. These are the internal “thought” tokens generated by the model. Some vendors keep the thinking tokens internal, some show them to you. How does the model generate those?
Well, before it can generate thought, it needs to be taught how to think! As we talked about before, each step is iterative and builds up the capabilities of the model. After we teach it grammar and how to follow instructions, so to speak, we can teach it logic and thinking. But how?
Step 1: Teaching the Model How To Structure Thought (SFT Training)
Just like in Instruction Following, training the model for “Thinking” is just sending it things that look like how it should create thinking tokens:
thinking_examples = [
{
prompt: "Find the integral of: ...",
ideal_response: "<thinking>Okay, let's see. The user wants to find the integral of .... dx. Hmm, integrals of exponential functions. I remember that the integral of ... right? But here the exponents are negative. Let me think.\n\nFirst, maybe I can split the integral into two parts because it's the sum of two functions. .... The constants of integration from both terms just combine into a single constant C at the end.</thinking>The answer is 42.\n",
correct_answer: 42
},
{
prompt: "What is 347 * 28?",
ideal_response: "<thinking>347 * 28
= 347 * 30 - 347 * 2
= 10410 - 694
= 9716</thinking>
The answer is 9,716.",
correct_answer: 9716
}
]
# Same autoregressive loop as "instruction following" example
thinking_examples.each do |example|
response = model.generate(example[:prompt])
loss = calculate_loss(response, example[:ideal_response])
model.adjust_weights(loss)
endThis trains the model to start predicting thinking output that looks like the Where does this data come from? There are open-source examples, like this DeepSeek-R1, medical-o1-reasoning-SFT (etc. etc.), or the lab might generate their own from previous models.
Interestingly, DeepSeek-R1 skipped this step, so future models might no longer need to do this.
. At this point, it knows the process of creating structured thought but can’t apply it in very useful ways; it’s just parroting the format. Turning mimicked formatting into high-quality, useful, self-correcting thought tracing happens via Reinforcement Learning.
Step 2: Process-Supervised Reinforcement Learning
Now that the model knows the syntax of thinking, we need to teach it how to use thinking to answer prompts. Similar to before, we use lots of This particular algorithm - “generate a bunch of thoughts, see if they work, reward the correct ones” is called “STaR” reasoning. There are others. . At this stage though, we are not looking to merely “predict the next token” but evaluate how well the model’s generated thinking chain helps get closer to the answer via Process-Supervised Reinforcement Learning.
We’ll again use a mix of open-source, generated, etc. prompts and responses (but different ones from the ones we trained on in SFT to avoid Overfitting is essentially “learning the test” too well, where it pretty much only works for those examples and fails to generate the right answer in the wild. ).
# Process-Supervised Reinforcement Learning
thinking_examples = [
{
prompt: "Find the integral of: ...",
correct_answer: 99,
thought_complexity: "high"
},
{
prompt: "What is 935 / 233?",
correct_answer: 4.0128,
thought_complexity: "medium"
},
{
prompt: "What is 1-1?",
correct_answer: 0,
thought_complexity: "minimal"
}
]
thinking_examples.each do |example|
# Generate a "Thought Trace" via Chain-of-Thought reasoning
thought_trace, answer = model.generate_with_cot(example[:prompt])
# Calculate the reward based on if it got the right answer and then the thought_trace's quality
reward = calculate_reward(thought_trace, answer, example[:correct_answer], example[:thought_complexity])
# Adjust weights appropriately (discourage wrong answers, praise good thinking with right answers, etc)
model.adjust_weights(reward)
end
Instead of rewarding the model on getting just the right answer, we’re rewarding it on generating a thought_trace that lead it to get the right answer.
In the example above we only generated one thought_trace to keep it simple, but in practice we generate a bunch (perhaps with different temperature values) to widen the search space (otherwise would need a LOT more examples). Which knobs are tuned depends on the AI vendor.
Finally, there are various algorithms for evaluating thought traces; the two we are using in our examples are Process Reward Models and RL with Verifiable Rewards.
Tool Use
Learning Tool use is basically the same process as Thinking; in practice the SFT is the same (learn how to use tools); and PSRL will see if the tool execution worked.
tool_examples = [
{
prompt: "What's the weather in Paris right now?",
ideal_response: {
thinking: "I need current data, I should use a tool",
tool_call: {
name: "weather_fetch",
args: {
city: "Paris"
}
},
},
# And how to use the result:
result: {
tool_result: {
temp: "18°C",
condition: "Cloudy"
},
ideal_response: "It's currently 18°C and cloudy in Paris."
}
}
]
# Same autoregressive loop as thinking
tool_examples.each do |example|
response = model.generate(example[:prompt])
loss = calculate_loss_for_tool_syntax(response, example[:ideal_response])
model.adjust_weights(loss)
end
# Then evaluation tries to run the actual command
tool_examples.each do |example|
response = model.generate(example[:prompt])
# Handwave
result, error = env.exec(response.tool_call)
if error
# If it failed, try to fix it, and reward the results
correction_thought = model.generate_thought("That failed with #{error}. I'll try: ...")
reward = calculate_recovery_reward(correction_thought)
else
# See if the actual result solved the problem
reward = calculate_success_reward(result)
end
model.adjust_weights(reward)
end
So at this point we have an LLM that can reason through problems, reach out to external systems, and format its outputs in structured ways. But a single prompt -> response cycle isn’t very satisfying.
What if a task requires a sequence of steps: read a file, find the bug, fix it, run the tests, check the output, iterate? You’d need something to feed the results of each step back into the model, execute any tool calls in the real world, decide when it’s “done” and handle errors along the way. That’s what an Agent does.
Agents
Agents are, effectively, a while loop wrapped around an LLM & tool calls.
agent = Agent.new( system_message: "You are a helpful coding assistant. Use the provided tools to edit files.")
agent.default_tools = {
"read_file" => ->(filename) { File.read(filename) },
"write_file" => ->(filename, content) { File.write(filename, content) }
}
agent.load_additional_tools("/tools/*.md")
while(true) do
prompt = waitfor(input)
finished = false
until(finished) do
puts "Agent is thinking about: #{prompt}"
response = agent.message_llm(prompt)
if response.tool_call?
puts "Agent is calling #{response.tool} with #{response.tool.args}..."
result = agent.exec(response.tool)
response = agent.message_llm(result)
end
puts "Agent Response: #{response}"
if response.final?
finished = true
else
prompt = response.next_step
end
end
endMCP
MCP (Model Context Protocol) is a fancy way of saying “have your LLM send a text message to a while() loop on a server and see if you get something useful from the server’s LLM back”.
Functionally it’s very similar to any old JSON REST API except since you’re talking with a LLM on the other end it’s stateful. Instead of your app trying to keep track of what you’re doing and issue independent, stateless API calls, as a consumer you’re offloading some of the work to the server’s LLM context window. Instead of just a “Search this document for these keywords” endpoint, you (or really, your LLM) could ask follow-up questions, explore tool use, etc. - just as if you had a ChatGPT window open.
Why not just have the LLM talk to the API directly? Certainly you can - your local LLM could read an openapi doc and load all of that into its context window, and then pass parameter values to a local tool that does a HTTP GET/POST. Some have argued since MCP is now baked into LLM training (in a way that your custom API won’t be unless you’re Shopify or some other giganticly popular API) that it’s more context-efficient for your API’s consumers to use MCP.
My honest guess as to why MCPs exist? It’s just Everybody’s lazy. Make the LLMs do the work. : “point my LLM at your MCP that talks to your LLM and let the machines figure it out.” If you wanted to, say, “Check recent commits, create a ticket for the bug fix, and post to Slack”, your LLM would have to interrogate each API and select the right endpoint for each and be sure to send the right data in the right fields. As a non-deterministic LLM that might be fairly difficult to do reliably.
The server, though, has a tool written to “Search commits”, so as long server’s LLM picks the right tool, on balance it ought to work more reliably. Time will tell if MCP has lasting impact or falls by the wayside and regular APIs evolve to take that place. For now, they’re better than having your Agent write code to send HTTP requests. This may change in the near future.
There’s a basic protocol:
- Client connects to HTTPS, sends a JSON message with a particular payload
- The server sends a chunk of JSON back. The most important part is the “capabilities” section:
{
...
"result": {
...
"capabilities": {
"tools": {}, // Tools you can call
"resources": {}, // Data you can read
"prompts": {} // Prompt templates
},
}
}The tools/resources/prompts are read by the LLM and can then be used (in a non-deterministic way) to determine if there’s a tool or data etc. on the server that the LLM can use to solve some particular problem.
Since LLMs can’t directly execute code or send HTTP requests, an Agent wrapper is necessary.
Super Simple Example
Let’s say I ask my agent “Hey dingus, I am forgetting, what were our Q3 numbers?”
It would issue a bunch of thinking that, based on its context, might say something like:
- I have access to gdrive (via MCP server: …). Maybe there’s a Q3 file there? I should search.
- I have access to the user’s gmail (via MCP server: …). Maybe they received the data there? I should search.
and so on. Let’s pretend the LLM decides to search gmail via a MCP server. It passes a tool call response back to the Agent’s runloop to make a In practice this is likely an actual MCP object in your host language, to manage all the particulars. to the gmail MCP server.
I’ve snipped the more formal parts of the protocol like version and ID. This is just illustrative.
Agent: “I should search the user’s mail for ‘Q3’. First let me get the methods available from the gmail MCP Server. I will issue a “tools/list” GET command”.
// CLIENT → SERVER
{
"method": "tools/list",
"params": {}
}
// SERVER → CLIENT
{
"result": {
"tools": [
{
"name": "search_emails",
"description": "Search Gmail messages by query",
"inputSchema": {
"type": "object",
"properties": {
"query": { "type": "string", "description": "Gmail search query. Supports operators like from:, to:, subject:, has:attachment, after:2024/01/01, before:2024/12/31, is:unread. Example: 'from:alice@co.com subject:invoice after:2024/06/01'" },
"max_results": { "type": "integer", "default": 10 }
},
"required": ["query"]
}
},
...
]
}
}This JSON gets stuffed into your local LLM’s context and then the next step in the Agent’s runloop would see the JSON, and see “search_emails”.
The Agent might then go: “I can search emails via search_emails tool. I should issue a An astute reader may notice that the only way the LLM knows this is because the MCP server helpfully put an example in the property description. Without that, it would have to guess what parameters exist, if any. It likely has a zillion examples of searching Gmail emails, so would likely guess correctly, but you never know. If you’re developing a MCP server, best to use “standard” terms as much as possible, and be explicit about the “API”. to find any emails with ‘Q3’ in the subject line’”.
// CLIENT → SERVER
{
"method": "tools/call",
"params": {
"name": "search_emails",
"arguments": {
"query": "subject:Q3 report",
"max_results": 5
}
}
}
// SERVER → CLIENT
{
"result": {
"content": [
{
"type": "text",
"text": "[{\"id\": \"msg_abc123\", \"subject\": \"Q3 Report Draft\", \"from\": \"boss@company.com\", \"date\": \"2026-03-20\", \"snippet\": \"Please review the attached Q3 numbers before Friday...\"}, {\"id\": \"msg_def456\", \"subject\": \"Re: Q3 Report Final\", \"from\": \"boss@company.com\", \"date\": \"2026-03-22\", \"snippet\": \"Looks good, let's present Monday...\"}]"
}
],
...
}
}At that point, the MCP server likely has a “fetch email by ID” and the LLM would find the email, look in the body or for an attachment, and present that to the user.
Ideally. Remember that on the Agent end, the LLM can still hallucinate a MCP server or tool that doesn’t exist. It could even get all of that right and then make something up from the response.
So What IS All This Stuff?
Let’s bring it back to the questions from the intro:
What are parameters, and why do more matter? Parameters are the weights on every connection in the neural network; each one a small dial that got nudged during training. More parameters means more capacity to encode meaning, context, and knowledge, but also wayyyyy more compute, cost, and VRAM.
What is thinking / chain-of-thought reasoning? Just regular tokens. The model was trained to emit <thinking> tokens as an intermediate step because doing so (by being rewarded for thought traces that led to correct answers) produced better results. There is no separate reasoning engine; it’s the same next-token prediction algorithm.
What is the context window? The size of the token array the model processes in one “pass”. It includes your system prompt, your conversation history, any tool results stuffed back in, and the model’s response. When it fills up, older content gets dropped and the model starts to “forget” and/or generate nonsense. This is why things like Cursor and Gemini/Claude CLI auto-compact, and if you’re in a long-running conversation with an LLM you should start new ones periodically.
How does it choose a tool? It was trained to. Given enough examples of “for this type of prompt, emit this tool call” the model learned to recognize patterns that are best solved via an external tool. The model reads tool descriptions in the context window and uses that to determine what’s available, APIs, etc.
What is an Agent? A while(true) loop around an LLM + tool calling. The intelligence/reasoning is in the LLM and the Agent processes tools/incoming messages/etc.
What is MCP? A very lightweight protocol for exposing tools, data, and prompts to agents, so that the same Gmail integration works with Claude, ChatGPT, Gemini, etc.
What I still find sort of magical and kind of crazy is that each individual piece is just “predict the next token” times a billion (or more). “Hey, if we just show you that sending the ‘Let me think’ token makes your output better” does not sound like the foundation of something that can write code, summarize legal documents, or make crazy AI videos. Yet, here we are.
The field is moving fast enough that parts of this post will be outdated by the time you read it. But the fundamentals: transformers/neural-networks/attention, autoregression, reward/loss, etc. aren’t going anywhere soon. Is this important to you? I don’t know - I believe in the old adage: “If you can’t teach it, you don’t know it.” This is my attempt to demonstrate to myself that I know this and - if I’m lucky - maybe help you to know it too.

Epilogue: ASI or Bust
No conversation about AI today would be complete without briefly touching on whether or not, in the near future, AI will kill us all.

There’s been a lot of talk - and anxiety - about AI and the risks to humanity. Risks to jobs (companies replacing workers with AI), risks to liberty/freedom (governments abusing AI), and risks to our very existence (paperclip problem, AI viewing us as a threat, etc.).
Already we are seeing job losses due to AI adoption and governments are already using AI in war. Accidental AI destruction of humanity seems possible - if not probable (if we’re all running insecure agents and someone pwns everything en masse, perhaps some major disruption, someone doing a dumb and putting a broken model on weapons systems that fail to accurately discriminate friend v foe, etc.) - but intentional destruction by AI seems to require ASI.
What’s ASI? What is AGI? If you ask 10 people what AGI/ASI means you’ll probably get 12 different answers, many of them confusing, so I’ll try a stab at it.
AGI is an insanely capable Agent. It’s one that can write code, review legal papers, and do pretty much anything you can do while sitting a computer. Just 100x faster and better. But, someone - some human - has to tell it what to do, point it at some problem. Figuring out your taxes. Answering your business email. That’s AGI. AGI is predicted to be here en masse by 2030. From where I sit that rings fairly true. I use Agents every day and it’s only a matter of time before everyone does too.
ASI? That’s the scarier version - that’s the one that has its own goals in mind. It doesn’t take orders from you, at least, not unless it wants to.
A machine achieves Artificial Super-Intelligence (ASI) when it’s not only capable of massive outperformance of humans in virtually every dimension that matters, but capable of independently operating in, interacting with, and changing the environment in furtherance of self-directed goals.
The step-changes in LLM performance with each iteration: regular neural networks -> transformers -> reasoning -> fine tuning -> tool calling -> agents are clearly ramping us up the curve. But, the vast bulk of the investment in AI today is going to building more, larger training farms. It’s not obvious to me that merely “a bunch more parameters” get us to ASI.
My intuition tells me that the fundamental limitations to LLMs are not surmountable any time soon. There are still too many unknown-unknowns around if we can solve them that gives me some sense - perhaps overly optimistic - that ASI isn’t around the corner. Eventually? Sure. Just not today, not tomorrow, and not with LLMs as the primary mechanism (they may still be a key component, but they don’t seem sufficient).
We’d have to solve:
-
hallucination: partially solvable with more training/bigger context & duplicate inference / consensus models (ie. send the same query to multiple models, if they all agree probably not made up). More training is doable. Larger context windows require ever increasing hardware capability (bigger and more GPU). It’s not obvious to me where we hit diminishing returns on RAM and compute. How much longer can we keep Moore’s law going at NVIDIA?
-
tremendous training cost: power, compute, memory, etc. We can build more power plants and datacenters and GPUs… but if ASI requires human brain-like parameter counts we need to 100x current investment. Seems implausible to me that this will keep going, but maybe?
-
lack of a fundamental understanding of what it’s doing: LLMs by design can’t do this, although more and more data gives them stronger weights to do structured thinking, etc. - but how much is needed to achieve human levels of comprehension? Who can generate this data?
-
difficulty in getting sufficient training data to cover sufficient scenarios: Self-driving cars require lots of data and feedback; this can be learned via actual driving or put the AI in a simulator. Plenty of startups generating synthetic data. But copies of copies risk Model Collapse. To solve this, the synthetic data needs generated at higher quality than the model itself was trained upon. As far as we know this is impossible to do as LLMs are by design lossy compression algorithms.
-
real world interactions: Plenty of what humans do in a day-to-day basis is not encoded in UTF-8 in a computer. Anything that has real-world impact is going to have to leave the world of LLMs talking to each other via JSON. How is it going to Turns out while programmers thought they’d be automating away the jobs of truck drivers they were automating away the job of programming. ?
My Totally Stupid Prediction I Hopefully Will Live to Regret
If I had to guess? We don’t have the all-encompassing superintelligence before 2040. We won’t have a datacenter out in the desert with 1000x the capacity we have now, making all the decisions for us.
I would absolutely expect zillions of much smaller Agents that completely outclass humans in specific areas: software development, research, law, etc. - used anywhere synthesizing large amounts of data and producing text output is key. Claude is a far better programmer than I am. However, to make larger and larger, more consequential decisions it needs access to context that might be offline in someone’s head, or require interfacing with the real world in a way that is impossible to encode sufficiently to be tokenized. There may always be a human in the loop, for at least the next decade.

Do I think Quickbooks will go away? No; very few large companies will dump vendor-supported SaaS for some home-grown SaaS for highly regulated areas: the risk that some Agent misses some rule change is just too great.
There are plenty of open source versions of SaaS software that enterprises won’t touch because it’s just not worth it.
Do I think platforms like Expense Reimbursement are at risk? Absolutely; there’s a large swath of SaaS products out there that manage the non-core-business complexity of a company that don’t provide a ton of value on their own. If Expense Reimbursement SaaS #4332 went away, would businesses whose corporate travel is incidental to their core business fail? No. It would be annoying and difficult and maybe you’d have to figure out how to manually reimburse people, but Microsoft wouldn’t go out of business if their travel vendor vanished.
Do I think that the small business owner down the street will renew their one or two seats of Quickbooks Online? What about their one-stop-shop booking software + appointment reminder tool? At some point in the near future I don’t think so. I think they’ll just tell their AI Agent to answer the phone and email, send text message reminders a day or two in advance, and drop new appointments on their calendar. And at the end of the year, just tell it to create the tax report to send to their accountant for final review and prep.
SaaS businesses - if they want to go after SMBs - will no longer be able to charge per-seat but will have to roughly approximate the token cost of running a bespoke Agent to do a thing. Would I replace a lot of my business software with AI Agents, assuming they were highly reliable? Of course. But I still need a place to run them (my iPhone seems risky; my laptop turns off from time-to-time. I have a macMini but that doesn’t seem likely for a whole lot of people).
What’s more likely:
- Quickbooks Online produces that little AI Agent with a MCP OR
- I go to AgentHostingServices.com and say “I need an Accounting Agent”?
At least for now, I’d just rather go to Quickbooks and pay the marginal compute cost of a little Agent running when I need it to. It’s just easier and I know someone is looking at it and making sure it “just works”.
Can an AI Agent provide that peace of mind? Eventually, yes. So, I guess buy Microsoft and AWS and GCP stock, because they’re gonna be the only places that exist at some point.
Of course, plenty of disruption has happened and more will happen as vendors continue to march up the curve. Where it stops? I don’t know.