It’s pretty clear we’re in the “disposable software era”. Plenty of blog posts chatting about it:
etc. Just google “Disposable software”
For the most part, though, the examples referenced are about small, bespoke solutions to particular problems, often short-lived and/or non-production coded stuff, or things like “LLM needs to do a thing so it spits out some python, executes it, and deletes it.”
We should be thinking of how “Disposable Code” in production helps us move faster and take advantage of the gazillions of dollars spent on AI. We long ago accepted that infrastructure should be disposable; why should we treat code like cattle, not pets?
Get over it
Some part of this argument is going to come down to “it just is, build a bridge and get over it.” This sucks. I wish that I could write terrible rails code and get paid $250,000 a year, but those days are quickly coming to an end. Maybe not today, maybe not tomorrow, but sometime soon. It doesn’t mean the end of software development (The spectre of AI taking all our jobs has always been a thing - we just thought it was a lot further away than it appears to today. The problem has always been there, we just thought we had more time. Oh well. ). It just means that the nature of the work is changing.
The way we wrote code prior to AI was akin to how people made furniture back in the olden days: with a high degree of quality and craftsmanship. If you wanted a chair, you’d have to learn to be a carpenter (or hire a master carpenter). Seating for 100 people? And you want chairs? Well, sorry, no you don’t, because that would take a decade and infinite money and several people would die in the process. You get a long bench and fill your building with those.
Then the industrial revolution came about and all of a sudden we could produce chairs by the boatload. The price dropped dramatically, and yes, the quality wasn’t as good.
Check out this really fancy old-timey desk:

It costs $38,000 and arrives in 24 to 36 weeks.
Check out this desk:

It’s $209 and I can get it delivered today.
They do the same job, right? There’s a tabletop and some drawers to hold things.  But the $38,000 desk is for someone that wants an artisanal desk that someone broke their back to make and is willing to pay for it. The rest of us load up our blue shopping cart and eat the meatballs.
But the $38,000 desk is for someone that wants an artisanal desk that someone broke their back to make and is willing to pay for it. The rest of us load up our blue shopping cart and eat the meatballs.
And now, humans went from artisans making hand-crafted code to operators of a non-deterministic AI machine that makes chairs code. So how do we take a non-deterministic token machine and produce high-quality, working code?
Plan to throw it away.
Throw it away?
We used to say that old code rusted. “Software rots” is a thing we’ve been talking about for a while. And we’ve all had an experience where you open up your editor, look at some code, scratch your head and say “Who wrote this garbage?” only to have git blame show you as the author.
Human thinking doesn’t scale. Large software doesn’t scale. Reading and understanding every line of code doesn’t scale. It never did, we have just been pretending. Let’s stop pretending.

We need to build a system with this in mind. Why?
A Simple Example
Back in the dark ages (late 2024/early 2025) at Studio Charter we needed a way for customers to get web access to onsite 4k video recordings.
This is complexified because:
- The files live on a USB SSD attached to an onsite ATEM
- ATEM only supports anonymous unauthenticated FTP access
- The Mac needs appropriate credentials to store the files “somewhere else” (aka the Cloud)
- Since the Mac is onsite with our customers - some of whom are coworking places - it could walk away at any minute, so each credential needs locked down to only be able to write to a specific per-customer per-video-studio storage bucket. It cannot read file data, delete anything, etc.
- After the files are uploaded to this storage bucket, they then get moved to a final location after some post-processing occurs (verification/validation, de-duping/cleanup, etc.)
- The user might be a guest who isn’t a member of the coworking space or an employee at the company that the studio is sitting in.
So we have to get files into a Ruby on Rails app that a person can click and download, or do light-duty editing on.
Since I’m using Rails for this we have some patterns. The normal approach, and how Rails’ ActiveStorage is architected, is that ActiveStorage handles the entire lifecycle of the file (initial upload, ActiveRecord object creation, etc.). However, it doesn’t make sense to have the Mac send its files to Rails - there could be dozens or hundreds of files, ranging in size from a few megabytes to tens of gigabytes. Throwing this at the Rails app is super expensive and failure-prone.
I needed a way to get the files off of the Mac, upload them to GCP, then somehow tell the Rails app that the files were there (or Rails could poll the directories) so that Rails could create the appropriate file objects. Back when I was doing this, I only had access to GPT4 and Claude 3.something, so I opened up chat windows and went back-and-forth with each, trying to get to a reasonable architecture.
We decided to do something like:
- The Rails app will generate appropriate GCP buckets when lifecycle events occur (new customers, new studios, etc.)
- :handwave: securely get the appropriate gcp keys on the Macs
- use rclone to sync the files from ATEM via the Mac
- GCP pub/sub would, once the whatever processing was complete and the files were moved into the final bucket, issue signed file bucket lifecycle event webhooks to the Rails app
- The Rails app would create appropriate ActiveStorage file objects for each one
This seemed reasonable. How to write all this code? I used ChatGPT web UI directly to have it generate the Rails code:
- GCP API calls to manage bucket creation etc.
- Inbound GCP Webhook processing
- GCP API calls for web file lifecycles (deleting the file, etc.)
Can I tell you? This code is terrible. We have the following Rails models:
GCPSyncGCPSyncItemGCPFileGCPConfiguration
This looks approximately fine, but when you dive into the details it’s written in a way that doesn’t make any sense. When the gcp_webhook_controller receives the ping, (via a background job) it sends the message to NotificationService, which creates a GCPSync and then a GCPFile directly for each file in the message.
We have a bunch of other service objects GPT created:
GCPConfigurationGCP::BucketOperatorGCP::FileOperatorGCP::IAMServiceGCP::RefreshServiceGCP::SecretManagerService
The NotificationService takes the GCP file payload and creates a GCPConfiguration item, and passes it to the Bucket and File operators, then finally creates the GCPFile object and associates the GCPConfiguration with it.
According to wc -l there are:
- 1335 lines of Ruby in the GCP service objects (+1676 lines of tests)
- 952 lines of Ruby in the various GCP models (+983 lines of tests)
The way it creates objects is weird; the order of things is weird; and there are lots of “keep poking at it to make it work” kinda hacks (ie. adding dependency injection purely to make testing easier; a simpler implementation would’ve made the testing easier and not required DI) - things that might cause a human to go “huh, I’m working too hard to do this, maybe I should re-think things”.
I had Opus 4.6 re-architect this and it dramatically cut back on objects; the GCPConfiguration was (roughly) a few attributes on the GCPFile, etc. - the combined code it spit out was 264 lines of code and looks a lot more sane/manageable. We were able to re-use the bulk of the relevant test suite - the build-evaluate-fix-rerun loop was pretty straightforward because of this. I haven’t tested it since this is not speed-critical code but I’m sure it’s faster to execute, and there are fewer tests, so the test suite certainly runs faster.
What are the aspects of this example that made this AI refactor successful? How was I able to easily throw away the old code and replace it? How can I trust that the code isn’t terrible, leaking secrets, or a total disaster? What does it take to write disposable code?
Disposable Code Manifesto
Generally speaking, to be trusted, AI-produced disposable code needs to:
- Do what you intend
- Meet particular requirements
- Be safe
Do what I intend
Waterfall was, for a dismal while, The Way to produce code. People would go in a deep cave and produce giant reams of paper describing every fine detail down to the semicolon. Humans were, essentially, very fancy typists that turned UML to zillions of Java classes.
We (rightfully) discarded this in favor of Agile development. Waterfall is bad because unshipped product is a liability - it’s muda. We need fast iterations with our customers to really understand their problems, propose solutions, and iterate, until we get it “just right”. Waterfall keeps us locked in our cubes until it’s too late.
Agile teaches us that long lead times are bad. That we need working software over documentation.
So how do we write code with LLMs? “Spec Driven Development” is, generally speaking, how we do it today.Isn’t this just waterfall for AI?
Kinda feels an awful lot like the Waterfall of the past (or something like cucumber - which I could never enjoy writing).
SDD isn’t really waterfall in that sense. LLMs are fuzzy compilers of intent to code. We don’t have to specify things to the n-th degree. We don’t need to specify that passwords should be hashed.
Why not?
LLMs already possess the world’s knowledge of Java-garbage-boilerplate, standard libraries, design patterns, and tools. It has slurped up OWASP and - thanks to the dedicated folks at AI labs - been beaten into submission that “thou shalt not put plaintext passwords in the database.”
I can just tell it “This is a Rails 8 app, I need a login page, use a gem wherever possible” and it will happily add Devise and/or OmniAuth and it will have the appropriate has_secure_password.
Yes, it is a form of “big design up front” but because of the fuzzy nature, it’s more like “small design up front” and because the execution of the spec is trending to “free” (in terms of time/effort, not necessarily token cost) we can see the results of that immediately.
Meet Particular Requirements
We can’t just blindly accept LLM code without reasonable acceptance criteria. A spec, in this case, isn’t really the acceptance criteria because it’s far too vague. It’s a context doc, describing what not how. “I’m using Rails 8. When a GCP Webhook comes in, we need to process that message and ensure a File object is attached to the right Company and Studio. The JSON is {..}. We should follow standard Rails background job best practices and ensure that we handle failures gracefully.”
The requirements are implemented (currently - maybe someone will come up with an AI-first way of doing this differently) as tests. Functional, unit, integration tests help us describe the behavior of the system.
A comprehensive test suite is necessary to hand off implementation to an LLM. Necessary, but not sufficient. It’s one leg of the stool.
Be Safe
Specs are lossy. Tests can help us with behavior. But implementation is not really the place for us to put tests. Can we write a test that looks for has_secure_password? Of course, but for a bunch of reasons we don’t want to test implementation. So how do we ensure that the software is safe to use? That it doesn’t leak our passwords and sensitive data, etc.?
We have a mix of structured and unstructured methods:
- Structured: we can use static code analysis, code quality systems, and linters to conduct rules and heuristic-based analysis.
- Unstructured: we can ask a consensus of different AI models to evaluate code on fuzzy areas, like security, performance, architecture, good coding standards, etc.
In Practice
What does this mean in a more than handwavy sense?
Do what I intend
The process I follow now is much more iterative than “One spec to rule them all”. I don’t one-shot things - or over-specify things.
I start with deeply understanding and interrogating the architecture. Once that is sound I find that everything else flows pretty quickly and I can spend less and less human time on each subsequent step.
Iterative coding & human involvement
I have the AI generate code iteratively in a “crawl, walk, run” approach:
- Crawl: Write the skeleton tests all failing, write the skeleton implementation so they pass. Human spends time reviewing.
- Walk: Flesh out simple implementation of these things. Less review than at #1, but still some effort.
- Run: Wire it all up, end-to-end tests all pass, etc. - far less review than the first two, if any.
- Send to another model to do targeted review - security, performance, etc.
The specs and the agent are a part of a pipeline and not operating in isolation.
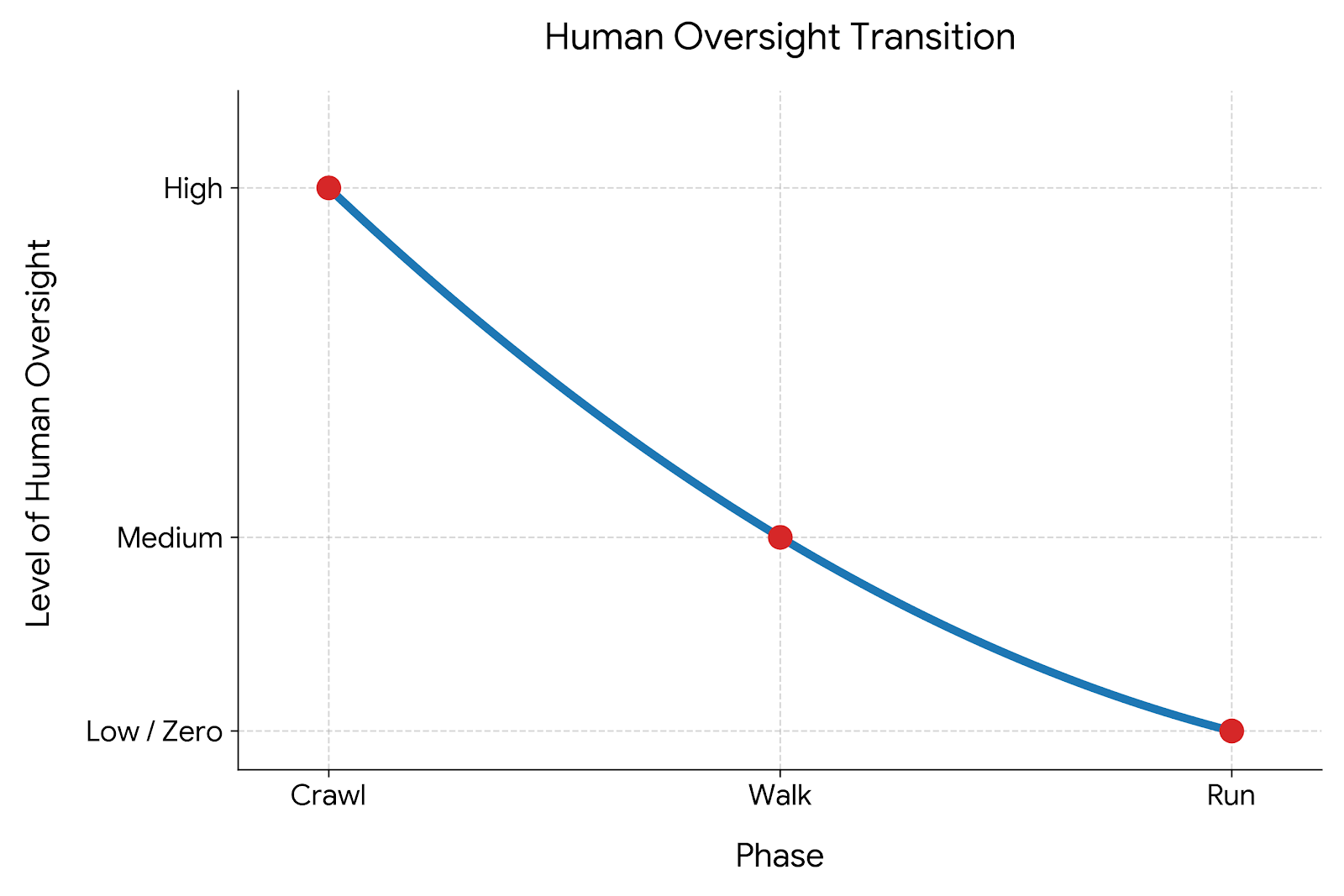
This allows me to stay in the loop so I understand what it’s doing and if we encounter any weirdness at any step it’s ideally earlier in the process so changes are fewer tokens and easier to do.
Then once the “bones” are solid and we have a comprehensive test suite? The AI can get cooking.
Meet particular requirements
Strong test suite
In the first step, I’m looking at the test suite much more closely than any other line of code the AI is writing.
My refactor was easy because I had a solid test suite. Much of the test code didn’t even need to change since I was still using GCPFile and many other primitives. If I didn’t have this I’d have been much more cautious about the major refactor.
Less is More
We all know the best code is code not written. This goes extra for AI-produced code. Not only does it cost more tokens to re-write things an existing library or framework holds, having the AI generate code increases the risk surface area for security, performance, and architectural problems.
Use Frameworks
There is a huge advantage to working with frameworks like Rails. The AI doesn’t have to make a whole lot of decisions: “models go in /app/models”, and there’s enough documentation and examples out there that if you say “Make me a model that does X” it should be able to one-shot it very efficiently/cheaply. The LLM doesn’t need to burn a bunch of tokens trying to figure out where you put your models in your bespoke framework. It “knows” where things go because it’s a Rails app.
Plus, it has seen so many examples of has_secure_password that asking it to “add a login page” is statistically hard to get it to generate plaintext password storage. You get more secure code out of the box if you’re using a framework than if you were building from scratch.
Use Other People’s Code & Documentation
ChatGPT4 wrote a bunch of code that should’ve been either not written at all or used a Ruby gem in my case; insert npm package, crate, library, whatever.
. This may have been a quirk of 4.0 but I now, in the architectural phase, explicitly tell the AI to look for existing libraries, and then I make sure a copy of the library documentation and/or source code is in my project, so the LLM knows where to go to get the “ground truth” of an API.
Why? First, the developer ergonomics/API of an existing library is likely “more correct” than whatever the LLM will produce because the sharp edges have been ground down via repeated contacts with actual end-user developers, edge cases, bug reports, etc.
Second, the library Maybe? Once LLMs produce everything how do I trust that devise gem still works? I’ll trust the Rails team to try their best to keep Rails secure, even if they are using LLMs. You still have to trust something, and if the day comes that the LLM is more trustworthy than Rails, then trust that.
and has fewer bugs; many eyes make bugs shallow and whatnot.
Finally, if it’s open-source or otherwise relatively popular, the library’s APIs are likely already in the model so it knows what to do without burning a lot of tokens, and the code that uses it will be better since the LLM isn’t inventing a whole API and how to use it: it already has an API and a lot of examples on how to do “X”, so the resulting code is a lot better. Even if it’s not a widely used library, having the code/documentation in the repo gives the agent a bunch of context to make better decisions.
Be Safe
Static Code Analysis/Linting/etc.
I also have rubocop and brakeman integrated into the project as well as a AGENTS.md that gives the “style guide” for how to do things. This gives me some safety as the AI can’t easily bypass these checks (it could if it did some evil commits you weren’t paying attention to, but there would be a paper trail).
Good Cop/Bad Cop
In both the architectural phase and after a set of features are written, I will point a different model at the AI’s output and ask it to critique it for security holes, regressions, test suite coverage, etc.; fancier shops have role-based Agents (you’re a security agent, etc.) that review the code in realtime or as part of a CI/CD pipeline.
Just wait and the AI Gets Better

Hair cut too short? Just wait, and it’ll fix itself. AI keeps getting better and better. All you have to do is wait.
If I had just told ChatGPT4 to re-write everything, it’s unlikely it would’ve given me a meaningfully different result, but the difference between GPT4 and Opus 4.6 is dramatic. The code quality is way better because the model is way better. With so much investment in this space continuing to compound, it feels a safe bet that “the next iteration of your favorite model” will produce better code than the previous version.
The neat thing is - if you have clear boundaries and pipelines, you can point an AI at a block of code, or a service, etc. and say “make this better” and it can do this without you needing to know what “better” means or you looking at what it did.
GCPFile Revisited
An astute reader might point out that the reason why I initiated the refactor was because the original code was “backwards”. But who cares, if I’m not the one reading it?
This is a good point - if I had never looked at it, I’d never have noticed. I was not able to mentally process the “weirdness” in the code until I had to pop into the Rails console one day to create a single GCPFile by hand - this required tons and tons of manual work that was backwards from my mental model. It’s not obvious to me I could’ve detected this ahead of time unless I really spent a lot of time looking at the code.
I initiated the refactor because of code smells that I discovered. That doesn’t scale. Telling an AI to “make the code better” requires a human to make a judgement call. How can we automate improvement?
How to select code to refactor
Periodically have an Agent (with a different, better model) review code that has already been written. Knowing what you know now, Agent, is this code good? Are there newly discovered vulnerabilities or techniques that could break this code? Should we re-write it?
Did it work?
But once the Agent has decided to refactor it, how do you know if the refactor worked?
Keep track of metrics for each service and/or semantic chunk of code.
Lines of Code might be a good metric to keep track of. Or perhaps it’s Cyclomatic complexity or test coverage? Did the refactor reduce LoC, complexity, or improve test coverage?
If you have good metrics, when it’s time to have the AI rebuild things you have quantitative metrics to see if the code is better than before.
Make that a part of the test suite to keep the LLM honest (although misalignment here could be disastrous!)
Our Shiny New Future
Working with Agents can be both easy and incredibly annoying.
“Hey dingus, move this thing over two pixels” is easy for a human to review. Doing that 100x in a row is exhausting. “Hey dingus, add a new kind of file that behaves like GCPFile but for AWS” is more difficult, but straightforward for a human to test and evaluate. “Hey dingus, make me S3” requires too much human oversight to be practical.
We’re still finding the right “zoom level” for agents but as we’re increasingly asking agents to do more, larger things, we’re absolutely outpacing our ability to keep up with it. We have to lean into this reality.
Since the cost of creating and re-writing code is effectively Of course it isn’t but any individual change is relatively cheap, token-wise. , and humans don’t have enough time to and energy to review everything, we should take our puny human attention and focus it where we can get the most leverage.
We should start thinking of our code as cattle, not pets. As long as we have a good test suite, automated linting/static code analysis, and a framework within which an agent can operate, the cost of rewriting code drops dramatically.
Our job as operators should be something more like (for new projects or large features, not “add a new checkbox to this page”):
- Ensure a good architecture. Get consensus models to give you a solid architecture.
- Decompose that into phases, do crawl-walk-run.
- Pay attention to this code evolution. Look at the test suite, look at the code. Does it seem right? If it doesn’t, goto 1 with the learnings and start over.
- After the code is in production, collect metrics and have Agents review and speculatively improve areas when it thinks there’s a deficiency.
Wait, haven’t I seen this before?
If you’re thinking this isn’t new, you’re right! I’m not sure why we are re-learning the agile lessons of before, but I guess we are just doomed to repeat it. If I have a strong test suite, combined with static code analysis/linting, I can safely re-write (refactor) code - if I have code and no tests, I’m hesitant to make any changes. This is Agile Software 101!
LLM-produced code doesn’t change these requirements, but it does make it a lot easier to move quickly and safely while not worrying too much (just the right amount?) about the code the AI just wrote.
Yeah but what about my job?
Yes, AI will undoubtedly have major impact on many folks - myself included - ability to earn enough money to survive. For now, though, the job isn’t just “making chairs”.
Software developers make more than just the chairs. They’re also making the floors, the framing, the ceiling, the insulation, the plumbing and electrical - the whole building that the chairs go into. And the nesting-doll nature of this means that - right now, for now - AI has a real hard time building something bigger than just the chair.
Understanding all of the nuances of “I need a way to seat 100 people” to know what to build - how best to solve the problem - is still difficult for an AI to incorporate (Is this for a church? Restaurant? Boat? Airplane? Who is sitting there? Why? For how long? What regulatory requirements are involved? Budget? Timeline? etc.)
This is where humans still have a large, dominant role in the process. Maybe for my lifetime? Maybe not. Hard to tell. So let’s abandon the notion that artisinal, hand-rolled code is here to stay. It’s just too expensive. AI code does the job just fine, for most things. Most software is Ikea, not the Resolute Desk. Some software is safety critical and whatnot so yes, someone much smarter than me will make math problems to prove it’s correct and that’s great. For the rest of us? Not so much.
Our job is to move from solving - and deriving job satisfaction from - “I need to build a chair” to “I need to make a restaurant.” (or “I need to make accounting software”). We need to build the systems that ensure the things we make are solving the problems the customer doesn’t state, doesn’t know, or can’t answer. We have to do the work that AI, for now, can’t do.