For the most part, though, the examples referenced are about small, bespoke solutions to particular problems, often short-lived and/or non-production coded stuff, or things like “LLM needs to do a thing so it spits out some python, executes it, and deletes it.”
# CONCEPTUAL PRE-TRAINING LOOPinternet_documents = crawl_internet()
internet_documents.each do|doc|# 1. Tokenize the entire document into an array of integers# In reality, this is done in chunks since the docs are probably too big. # ATFLLM (Ask The F.. LLM) to learn about different chunk sizes. tokens = tokenizer.encode(doc)
# Inputs are tokens 0 to N-1# ["The", "capital", "of", "France", "is", "Paris", "and", "its", "population", "is", "about", "2", ...] inputs = tokens[0...-1]# Labels are tokens 1 to N (The "Answer" is just the next token)# ["capital", "of", "France", "is", "Paris", "and", "its", "population", "is", "about", "2", "million", ....] labels = tokens[1..-1]# 2. THE FORWARD PASS# The model predicts the probability for EVERY token in the sequence at once # (this is magic that GPUs provide since they are embarrassingly parallel) predictions = model.predict(inputs)
# 3. THE LOSS (The "Grade")# We compare the predicted probability of the 'correct' next token # to the actual token that was in the text. # Lower number is better. loss = calculate_loss(predictions, labels)
# 4. THE BACKWARDS UPDATE# Nudge the weights prior to this so that (for example) # 'is' predicts 'about' more strongly next time. model.adjust_weights(loss)
end
# Process-Supervised Training (Thinking)deftrain_thinking_step(prompt, ground_truth_answer)
# 1. Generate a "Thought Trace" (Chain of Thought) thought_trace = model.generate_thoughts(prompt)
# 2. EVALUATE THE PROCESS (The "Secret Sauce")# We use a Process Reward Model (PRM) to grade each step step_rewards = thought_trace.map do|step| process_reward_model.grade(step) # Is this step logical?end# 3. EVALUATE THE OUTCOME final_answer = model.generate_final_answer(prompt, thought_trace)
outcome_reward = (final_answer == ground_truth_answer ? 1.0 : 0.0)
# 4. REINFORCEMENT LEARNING# We update the weights based on the SUM of the step rewards total_reward = step_rewards.sum + outcome_reward
model.update_weights_via_ppo(total_reward)
end
defgenerate_with_cot(prompt, number_of_samples=10)
trajectories =[] number_of_samples.times do# We sample with Temperature > 0 to encourage exploration# Higher values create more hallucinations as it starts to # drift further and further from the training data. thought_trace = model.generate( prompt,
max_tokens=8192,
temperature: 0.8 )
trajectories << { thoughts: thought_trace.thoughts, answer: thought_trace.answer }
endreturn trajectories
end
defcalculate_reward(thought_trace, final_answer, correct_answer, thought_complexity)
# Step 1: RL VR # If it's wrong we need to negatively reinforce this pathreturn-1.0unless final_answer == correct_answer
# Base reward for being right reward =1.0# Step 2: Evaluation via Process Reward Model helpfulness, correctness, coherence, complexity, verbosity = process_reward_model.evaluate(thought_trace)
# Did it actually 'think' or just guess?# Various models might tune these all differently reward +=0.2if helpfulness >0.5&& coherence >0.5 reward -=0.2if correctness <0.5|| complexity >0.5# And so on# Token efficiency check: # If the thought trace is 10,000 words for a 2+2 problem, penalize it. reward -=0.2if verbosity >0.5return reward
end
defcalculate_loss_for_tool_syntax(response, ideal_response)
reward =0.0# This is handwavy to keep the code simple# We needed a tool, they didn't get it# Could still be helpful so don't kill it entirely reward -=0.5if response.didnt_use_tool?
# Picked the wrong tool - big problem reward -=1.0if response.tool != ideal_response.tool
# We know we needed to use the right toolif response.tool == ideal_response.tool
reward +=0.5if is_valid_tool_call(response.tool_call)
reward +=0.3else# A broken tool call is bad, we don't want to learn wrong syntax reward -=1.0endend reward
end
For as much as AI has dramatically changed all of our lives, mine included, I was a bit uneasy that I didn’t really know how they are implemented and how they work. What is thinking and chain-of-thought reasoning? How does it choose a tool? What are parameters, exactly, and why are more of them better? What’s an Agent? What’s MCP?
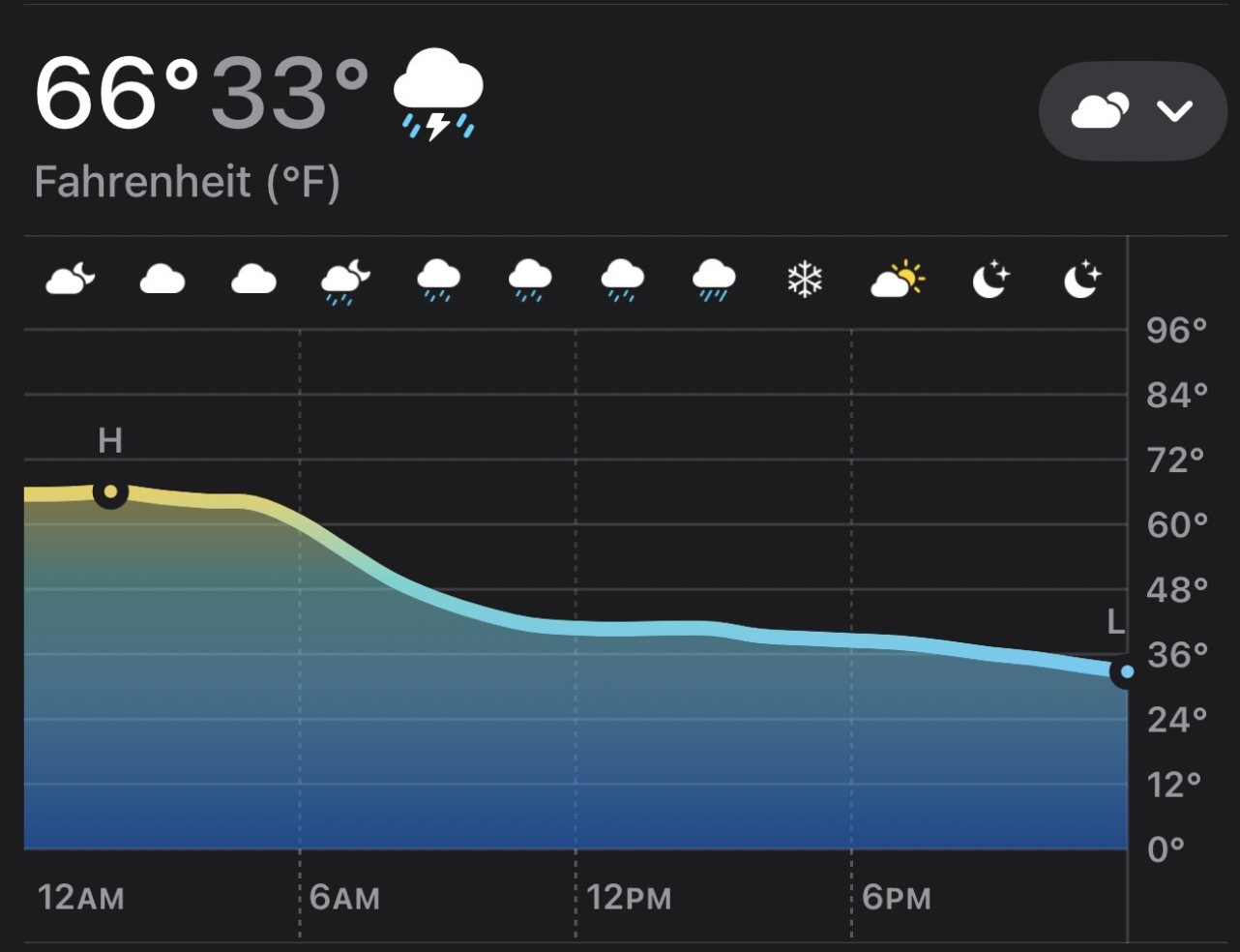
Looks like thunderstorms tomorrow. The high temperature will be 66 degrees, and low will be 33.
So you go outside with an umbrella and a t-shirt only to realize that it’s nearly snowing when you’re out. Why? Because of a chart that looks like this:
“Hey Siri, play Toxic”. And then “Toxic” by Britney Spears plays instead of the one in my library that I already listened to today (BoyWithUke)!
It’s no secret that AI-produced slop is filling up social networks, websites, blogs, job search sites, homework. B2B marketers have completely clogged the internets here and - perhaps because they lack the confidence, or just value the convenience - I see clearly AI-produced “personal” content in Slack groups, newsletters, mailing lists and Discords of all shapes and sizes.
And I get it. The pull is undeniable. The magical autocomplete super tempting. I keep trying to resist; when I’m typing out a post I will have Sonnet critique my work and I have to fight taking the suggestions verbatim. To quote the famous Jim Gaffigan: “Hey, that’s something I’d say!”