Facts do not cease to exist because they are ignored.
In my last post, I discussed why software effort estimation was harmful. I mentioned that you can’t add up all the individual tasks to get a completion date at some arbitrary point in the future, and you can’t (with some caveats) use estimation to “staff up” a project from the beginning.
Where does this leave us? Should we not estimate at all? These folks think so:
- Good Agile, Bad Agile
- Do not estimate software projects at all
- Impact of Schedule Estimation on Software Project Behavior
And even if you could estimate, they’re always wrong because of the difficulty in estimation coupled with the inherent variability of development:
- Saving for a Rainy Day
- The Challenge of Productivity Measurement
- Understanding Software Productivity
- Engagement Level and Impact on Productivity
How We Estimate

At work, we use relative points-based estimation where 1 point = small, 2 points = medium, and 3 points = large (large stories are almost always broken into smaller stories before development begins). We have a guide that gives representative stories for each size point.
Initially we fill our backlog with a large number of stories, broken down into individual deliverable units (e.g. “user can login”, “system sends email reminders”). We take a rough estimate of size (for some reason a well-gel’ed team can agree on relative sizes without too much difficulty) and use that for basic prioritization.
We then pull items off of the top of the backlog and work on them. As we go, if a story feels “too big” it’s broken up into smaller tasks. In general, no one should work on a “large” story - it should be decomposed into small and medium sized stories.
We can use velocity and “gut feel” to continually keep the backlog stacked with a few weeks worth of stories, ensuring that each developer has enough work to keep them busy (Google’s “Priority Queue”).
Why Points?
Points reflect that software development is inherently a chaotic and un-knowable endeavor, full of uncertainty and icebergs. But, this doesn’t allow us to abandon accountability or plan for the future. We’re professionals, and we act like it. Points lets us spend our incredibly valuable and scarce time working on what we do best: crafting amazing software, not agonizing whether feature X will take Y or Z “ideal hours”.
Points also reflect that a given story contains the same amount of risk or size no matter who works on it. Switching from PostgreSQL to MongoDB represents the same amount of risk and relative effort no matter who works on it.
Lingering Questions
There were a few questions raised in the last article that I’d like to address.
- How do we know how to staff a project?
- When will it be done?
- How will we make internal/external commitments?
How do we know how to staff a project?
If you look at the best estimators, they have a few things in common:
- Teams are fixed (no churn in developers)
- They have a lot of historical data to depend on
- They are often working on few, long-term projects or many projects that are very similar
These things typically only exist at large, established companies. Those that probably operate under a waterfall-type model - minimize risk and cost. The software they create is rarely used to disrupt entrenched markets but to claw share from competitors
- and viewed under this lens it makes sense that any given software project at these companies generates little measurable value and so requires the most control.
(This post is not for people working at those companies, although I think given enough prodding, you could get your management to be more flexible.)
But - if you’re asking “how many people?” then you’re removing the main support of effective estimation - that is, fixed team composition. Historical data estimation only works if you have the same people working on the future project. Otherwise, the estimates are significantly less valuable, especially in the short run as teams of new people fight to “gel” (and don’t forget the mythical 10x developer).
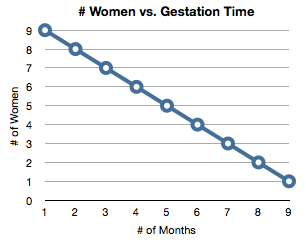
More interestingly, though, is that each additional programmer past a certain number gives diminishing returns. This is something (generally) not accounted for in historical data. You can’t take the performance of a four person team and multiply it by ten to achieve the performance of a forty person team.
If you have n-number of “programmer months” you also can’t simply throw a large number of developers at the project to get it done “faster” (also known as schedule compression).
The larger the team, the less schedule compression you achieve, and the greater diseconomies of scale. It sounds surprising at first, but intuition should help. If it took five people a year to work on a project, would it take ten to finish in six months? Maybe, but that seems doubtful. Not everything on a software project can be worked in parallel. Gut intuition tells you that it should be done later than 6 months.
What about twenty people. Could you get it done in three months? That seems a lot less likely. What about forty people? Could forty programmers get it done in a month and a half? Absolutely not.
The data backs this up:
- Haste Makes Waste When You Over-Staff to Achieve Schedule Compression
- Top Performing Projects Use Small Teams
- Small Teams Deliver Lower Cost and Higher Quality
- Mythical Man-Month Surgical Team
So what might account for these results? Over three decades of data from the QSM database suggest that defect creation and density are highly correlated with the number of people (and hence communication paths) present on a given project. Larger teams create more defects, which in turn beget additional rework. Fixed code must be retested and the team may find new defects injected during rework. These unplanned find/fix/retest cycles take additional time, drive up cost, and cancel out any schedule compression achieved by larger teams earlier in the lifecycle.
Conclusion: Minimize team size. The “optimal” size of teams is relatively fixed (less than five developers). “How many developers should we have on this project?” is the wrong question to ask.
“How can we subdivide the project into 2-4 person teams” is the right question, and planning can help with that. I’ve never had estimation be a high-order term in the equation, though. Generally putting a list of all of the different features broken into small chunks, organized by rough size (Small, Medium, Large) seems to work just fine.
I think a key point of this is on larger software projects, you must subdivide the work into separate components that don’t rely on shared state, etc. between them. This means your different components will act via message passing and an API.
Steve Yegge’s infamous “API ALL THE THINGS” post is a good example. It’s not an exact fit, but if you squint a bit and cross your eyes so you can see through the picture, you get an idea of what I mean.
When will it be done?
What does “done” mean? There’s always a feature you can add. Always some refactoring or improvements to make. “Done” is just an arbitrary pile of features that are “good enough” to be shipped.

What seems to happen most often is that over time, software never gets “done” because developers don’t have a clear “done” criteria. This leads to software built very wide (lots of features) but not very deep (not fully “done”), leading to the age-old “90/90” rule.
Even if a feature has well-defined “done-ness” estimation has a strong anchoring effect that encourages “90%” done features. If you estimate a feature to be eight hours but it really takes twenty to be “done”, in most companies you’ll receive pressure to compromise on quality or take shortcuts because you’re “taking too much time”.
Absent external pressure, I’ve often seen developers put too much emphasis on the initial estimate - even if there’s no manager breathing down their neck, the selfsame developer will feel guilty that they are taking “too long”.
Conclusion: Features should be fully “done” before moving on to other features. Avoid anchoring effect and be willing to invest the appropriate time to release high-quality code.
How will we make internal/external commitments?
The creation of genuinely new software has far more in common with developing a new theory of physics than it does with producing cars or watches on an assembly line.
This is a hard problem. I argue that building software is a lot closer to writing poetry than building a bridge. Ask a poet how long until the sonnet is written and you’ll get a blank stare.
Unless you’re building something very similar to something you’ve done before, you’re fundamentally creating something that has never existed before. Even the most “scientific” estimates contain a large chunk of risk (or “unknown unknowns”) that cannot be quantified ahead of time.
If you must make a commitment to a random date in the future and scope is fixed, you’re almost always screwed. Agile development helps avoid this by encouraging (requiring?) incremental development. Start working on the most important features first; aim for always shippable/deployable software by keeping the features small.
In this manner, you’ll always have working, testable software and will be moving towards the goal. Your customer/stakeholder will see the progress (or lack thereof) instantly, and be able to re-prioritize as necessary. Since you’ve got shippable software at every point in the game, Marketing and Sales can accurately inform customers on what’s going to be in the next release in a “just-in-time” fashion.
Many software companies have been abandoning announcing arbitrary dates for their latest products and announcing at conferences and tradeshows because it’s too restrictive and places their development on someone else’s timeline.
When Apple does a product announcement, the software has been in a feature freeze for months, and the hardware inventory has already been piling up. They don’t release handwavy dates “sometime next year” because they give a date once they’re already finished (iOS betas are more or less feature complete: Apple spends a long time polishing and fixing bugs, but no major features are usually released once the betas are released to the public.)
And, the functionality that is delivered is not promised ahead of time. I suspect Apple has a high level roadmap and works on the most important features first and cuts anything that isn’t ready or good enough.
If Microsoft and Apple can’t predict the future, what chance do you have?
Conclusion: Work on the most valuable features first in an iterative fashion. Always be delivering working software.

How to be Successful With Minimal Estimating - Build Small Software
Many small things make a big thing.
Since team productivity is maximized with smaller team size, effort is fixed, and software is inherently unpredictable, this leads to an interesting conclusion: don’t build big software projects.
Large software projects are cost/productivity inefficient. Large software projects contain a large amount of risk that cannot be determined a priori. Large software projects fail more often than smaller ones.
- Use rough approximations of feature size for high-level planning and guidance
- Use small teams to build small software
- Deliver frequently, working on the highest-value features first
- API all the things to enable different teams to integrate via a standardized API